utf-8 - codificación de caracteres
Unicode admite casi todos los existentesjuegos de caracteres. La mejor forma de codificación de conjunto de caracteres Unicode es la codificación utf-8. Proporciona compatibilidad con ASCII, resistencia a la corrupción de datos, eficiencia y facilidad de procesamiento. Pero sobre todo en orden.
Formas de codificación
Las computadoras operan con números no solo comoobjetos matemáticos abstractos, pero como combinaciones de unidades de almacenamiento y procesamiento de información de tamaño fijo - bytes y palabras de 32 bits. El estándar de codificación debe tener esto en cuenta al determinar la forma en que se representan los caracteres por los números.
En los sistemas informáticos, los enteros se almacenan enceldas de memoria en el tamaño de 8 bits (1 byte), 16 o 32 bits. Cada forma de codificación Unicode determina qué secuencia de celdas de memoria representa un número entero que corresponde a un carácter particular. El estándar proporciona tres formas diferentes de codificación de caracteres Unicode: bloques de 8, 16 y 32 bits. En consecuencia, se llaman utf-8, UTF-16 y UTF-32. El nombre UTF significa formato de conversión Unicode. Cada una de las tres formas de codificación es un medio igual de representar caracteres Unicode, tiene ventajas en diversas aplicaciones.
Estas codificaciones se pueden usar pararepresentación de todos los caracteres Unicode. Por lo tanto, son totalmente compatibles para soluciones por diferentes razones utilizando diferentes formas de codificación. Cada codificación se puede convertir de forma única en cualquiera de las otras dos sin pérdida de datos.

Principio de no imposición
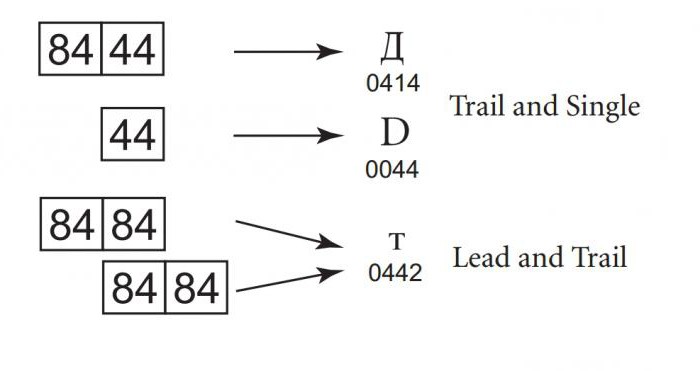
Cada uno de los formularios de codificación Unicode está diseñado conteniendo en cuenta la inadmisibilidad de la superposición parcial. Por ejemplo, Windows-932 genera caracteres de uno o dos bytes de código. La longitud de la secuencia depende del primer byte, por lo que los valores de bytes iniciales en la secuencia de dos bytes y un solo byte no se cruzan. Sin embargo, los valores del byte simple y el byte de cierre de la secuencia pueden ser los mismos. Esto significa, por ejemplo, que cuando busca el carácter D (código 44), puede encontrarlo erróneamente ingresando la segunda parte de la secuencia de dos bytes del carácter "D" (código 84 44). Para determinar qué secuencia es correcta, el programa debe tener en cuenta los bytes anteriores.
La situación se vuelve más complicada si el líder y el finallos bytes coincidirán. Esto significa que para revertir la ambigüedad, se realizará una búsqueda inversa hasta el comienzo del texto o una secuencia inequívoca de código. Esto no solo es ineficiente, sino que no está protegido contra posibles errores, ya que un byte malo es suficiente para que todo el texto sea ilegible.
El formato de conversión Unicode evitade este problema, porque los valores de la unidad de almacenamiento de información principal, de cierre y única no coinciden. Debido a esto, todas las codificaciones Unicode son adecuadas para buscar y comparar, nunca dando un resultado erróneo debido a la coincidencia de diferentes partes del código de carácter. El hecho de que estas formas de codificación observen el principio de no asignación las distingue de otras codificaciones multibyte de Asia oriental.
Otro aspecto de la no intersección de las codificaciones Unicodees que cada personaje tiene límites claramente definidos. Esto elimina la necesidad de escanear un número indeterminado de caracteres previos. Esta característica de las codificaciones a veces se llama auto sincronización. La distorsión de una unidad de código dará lugar a la distorsión de un solo personaje, y los caracteres que lo rodean permanecerán intactos. En el formato de conversión de 8 bits, si el puntero se refiere a un byte que comienza con 10xxxxxx (en codificación binaria), se necesitan de una a tres transiciones inversas para encontrar el comienzo del carácter.
Consistencia
El Consorcio Unicode es totalmente compatible con todos3 FORMAS codificaciones. Es importante no oponerse a UTF-8 y Unicode, como todos los formatos de conversión - igualmente formas válidas de realización de la codificación de caracteres Unicode estándar.
Orientación por bytes
Para representar el símbolo UTF-32, necesita una unidad de código de 32 bits que coincida con el código Unicode. UTF-16: de una a dos unidades de 16 bits. Y utf-8 usa hasta 4 bytes.
La codificación utf-8 fue creada para compatibilidad consistemas orientados a bytes basados en ASCII. La mayor parte del software existente y la práctica de la tecnología de la información durante mucho tiempo se basó en la representación de caracteres en una secuencia de bytes. protocolos múltiples depende de la constancia de la codificación ASCII y utiliza bien evita los caracteres de control especiales. Una forma sencilla para adaptarse a situaciones Unicode puede, utilizando la codificación de 8 bits para la representación de caracteres Unicode, cualquier carácter ASCII equivalente o un carácter de control. Para esto, se pretende la codificación utf-8.
Longitud variable
utf-8 es una codificación de longitud variable que consiste enUnidades de almacenamiento de información de 8 bits cuyos bits de orden superior indican a qué parte de la secuencia pertenece cada byte. Un rango de valores se asigna para el primer elemento de la secuencia de código, el otro para los elementos posteriores. Esto asegura una codificación disjunta.

ASCII
La codificación utf-8 es totalmente compatible con los códigos ASCII(0x00-0x7F). Esto significa que los caracteres Unicode U + 0000-U + 007F se convierten en un solo byte 8 0x00-0x7F utf-y por lo tanto se convierten en indistinguibles de ASCII. Por otra parte, para evitar la ambigüedad, el valor 0x00-0x7F no se utiliza más en una sola representación byte de caracteres Unicode. Para codificar símbolos neideograficheskih distinto de ASCII, usando una secuencia de dos bytes. Símbolos oscilan U + 0800-U + FFFF están representados por tres bytes, y códigos adicionales con más de U + FFFF requieren cuatro bytes.
Ámbito de aplicación
La codificación utf-8 generalmente se prefiere en el protocolo HTML y es similar a ella.
XML se convirtió en el primer estándar con soporte completocodificaciones utf-8. Las organizaciones involucradas en la estandarización también lo recomiendan. El problema del soporte en direcciones URL que no sean caracteres ASCII se resolvió cuando el consorcio W3C y el grupo de ingeniería IETF acordaron codificar todas las URL exclusivamente en utf-8.
La compatibilidad con ASCII facilita la transición a un nuevosoftware. Con utf-8, la mayoría de los editores de texto funcionan, incluidos JEdit, Emacs, BBEdit, Eclipse y el Bloc de notas del sistema operativo Windows. Ninguna otra forma de codificación Unicode puede jactarse de tal soporte de las herramientas.
La ventaja de la codificación es queconsiste en una secuencia de bytes. Con cadenas utf-8, es fácil trabajar en C y en otros lenguajes de programación. Esta es la única forma de codificación que no requiere el marcado del orden de los bytes BOM o la declaración de codificación en XML.

Self-Sync
En un entorno que utiliza el procesamiento de caracteres de 8 bits, en comparación con otras codificaciones de varios bytes, utf-8 tiene las siguientes ventajas:
- El primer byte de la secuencia de código contiene información sobre su longitud. Esto aumenta la eficiencia de la búsqueda directa.
- Es más fácil encontrar el comienzo del carácter, ya que el byte inicial está limitado a un rango fijo de valores.
- No hay intersección de valores de bytes.
Comparación de ventajas
la codificación utf-8 es compacta. Sin embargo, cuando se utiliza para la codificación de caracteres de Asia oriental (chino, japonés, coreano, chino escrito utilizando signos) utiliza secuencias de 3 bytes. También UTF-8 codifica inferior a otras formas de codificación de velocidad de procesamiento. Una clasificación de cadena binaria produce el mismo resultado que una ordenación binaria Unicode.
Esquema de codificación de caracteres
El esquema de codificación de caracteres consiste en un formulariosímbolos y método para las unidades de código de posición de un solo byte de codificación. Para determinar el esquema de codificación estándar Unicode proporciona el uso de una marca inicial de orden de bytes (marca de orden de lista de materiales, Byte).
Cuando la BOM está habilitada en utf-8, la función de etiquetaestá limitado solo por la indicación del uso de la forma de codificación. No hay problemas para determinar el orden de los bytes en utf-8, ya que su tamaño de unidad de codificación es de un byte. El uso de BOM para este formulario de codificación no es obligatorio ni recomendado. La lista de materiales puede aparecer en textos convertidos a partir de otras codificaciones que utilizan la marca de orden de bytes o para la firma de codificación de utf-8. Es una secuencia de 3 bytes de EF16 BB16 BF16.

Cómo establecer la codificación de utf-8
En HTML, la codificación de utf-8 se establece usando el siguiente código:
˂head˃
˂meta http-equiv = "Content-Type" content = "text / html; charset = utf-8" ˂
En PHP, la codificación de utf-8 se especifica utilizando la función de encabezado () al principio del archivo después de establecer el valor del nivel de salida de error:
Ph? Php
error_reporting (-1);
encabezado ("Content-Type: text / html; charset = utf-8");
Para conectarse a bases de datos MySQL, la codificación de utf-8 se establece de la siguiente manera:
Ph? Php
mysql_set_charset ("utf8");
En los archivos CSS, la codificación de caracteres utf-8 se especifica de la siguiente manera:
@charset "utf-8";

Al guardar todo tipo de archivos seleccionadoscodificando utf-8 sin BOM, de lo contrario el sitio no funcionará. Para ello, en el programa DreamWeave, debe seleccionar el elemento de menú "Modificaciones - Propiedades de la página - Título / Codificación", cambiar la codificación a utf-8. Luego debe volver a cargar la página, desmarque la casilla "Conectar Firmas Unicode (BOM)" y aplique los cambios. Si cualquier texto en la página o en la base de datos ha sido ingresado por otro formulario de codificación, entonces debe ser reingresado o recodificado. Cuando se trabaja con expresiones regulares, es obligatorio usar el modificador u.
También puede guardar el archivo en codificación utf-8 en el Bloc de notas de Windows. Después de seleccionar el elemento de menú "Archivo - Guardar como ...", configure el formulario de codificación necesario y guárdelo en codificación UTF-8.
En el editor de texto Notepad ++, si la codificación es diferente de utf-8, cambie la codificación y guárdela en codificación utf-8 a través del elemento de menú "Convertir a utf-8 sin BOM".

No hay alternativa
En el contexto de la globalización, cuando las políticas ylos límites del lenguaje se borran, los conjuntos de símbolos que tienen características locales se vuelven menos útiles. Unicode es el único conjunto de caracteres que admite todas las localizaciones. Y utf-8 es un ejemplo de la implementación correcta de Unicode, que:
- admite una amplia gama de herramientas, incluida la compatibilidad con la codificación ASCII;
- es resistente a la corrupción de datos;
- simple y efectivo en el procesamiento;
- no depende de la plataforma.
Con el advenimiento de la discusión de utf-8 acerca de qué forma de codificación o juego de caracteres es mejor, no tuvieron sentido.








