Regresión logística: modelo y métodos
Métodos de regresión logística y el análisis discriminante se usa luego,cuando es necesario diferenciar claramente a los encuestados por categorías objetivo. En este caso, los grupos mismos están representados por los niveles de un único parámetro univariante. Consideremos en detalle modelo de regresión logística, y también averigua por qué es necesario.
Información general
Un ejemplo de un problema en la solución del cual regresión logística, una clasificación de los encuestados segúngrupos que compran y no compran mostaza. La diferenciación se lleva a cabo de acuerdo con las características sociodemográficas. Entre ellos, en particular, se incluyen edad, sexo, número de familiares, ingresos, etc. En las operaciones existen criterios de diferenciación y variable. Este último codifica las categorías objetivo, que, de hecho, necesitan separar a los encuestados.
Matices
Cabe señalar que el rango de casos en los que regresión logística, es mucho más estrecho que para el discriminanteanálisis. En este sentido, el uso de este último como método universal de diferenciación se considera preferible. Además, los expertos recomiendan comenzar estudios de clasificación con análisis discriminante. Y solo en caso de incertidumbre para los resultados podemos usar la regresión logística. Esta necesidad se debe a algunos factores. Regresión logística Se usa cuando hay una comprensión clara de latipo de variables independientes y dependientes. De acuerdo con esto, se selecciona uno de los 3 posibles procedimientos. Con análisis discriminante, el investigador siempre trata con una operación estática. Implica una variable dependiente y varias variables categóricas independientes con una escala de cualquier tipo.
Tipos
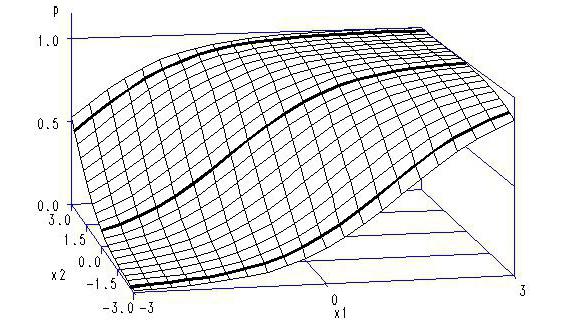
La tarea de la investigación estadística, que utiliza regresión logísticaes determinar la probabilidad de queun determinado encuestado será asignado a un grupo en particular. La diferenciación se lleva a cabo según ciertos parámetros. En la práctica, de acuerdo con los valores de uno o varios factores independientes, es posible clasificar a los encuestados en dos grupos. En este caso, regresión logística binaria. Además, los parámetros especificados pueden ser utilizadoscuando se divide en grupos de más de dos. En esta situación, hay una regresión logística multinomial. Los grupos resultantes se expresan mediante los niveles de una sola variable.
Ejemplo:
Supongamos que hay respuestas de los encuestados a la pregunta desi están interesados en la propuesta de adquirir un terreno en los suburbios de Moscú. Las opciones son "no" y "sí". Es necesario averiguar qué factores ejercen una influencia primaria en la decisión de los posibles compradores. Para hacer esto, a los entrevistados se les hacen preguntas sobre la infraestructura del territorio, la distancia a la capital, el área del sitio, la presencia / ausencia de una estructura residencial, etc. Usando la regresión binaria, los encuestados pueden dividirse en dos grupos. El primero incluirá a aquellos que estén interesados en adquirir: compradores potenciales, y el segundo, respectivamente, aquellos que no estén interesados en dicha propuesta. Para cada encuestado, además, se calculará la probabilidad de ser asignado a una categoría.
Características comparativas
La diferencia de las dos opciones mencionadas anteriormente,consiste en un número diferente de grupos y el tipo de variables dependientes e independientes. En una regresión binaria, por ejemplo, se estudia la dependencia del factor dicotómico en una o más condiciones independientes. Este último puede tener cualquier tipo de escala. La regresión multinomial se considera una variación de esta opción de clasificación. En él a la variable dependiente hay más de 2 grupos. Los factores independientes deben tener una escala ordinal o nominal.
Regresión logística en spss
En el paquete estadístico 11-12, un nuevovariante de análisis - ordinal. Este método se usa en el caso cuando el factor dependiente se refiere a la misma escala (ordinal). En este caso, las variables independientes se seleccionan de un tipo específico. Deben ser ordinales o nominales. La clasificación por varias categorías se considera la más universal. Este método se puede utilizar en todos los estudios en los que regresión logística Mejora la calidad del modeloSin embargo, solo es posible con la ayuda de las tres técnicas.

Clasificación ordinal
Vale la pena mencionar eso antes en el paquete estadísticono se proporcionó una posibilidad típica de realizar un análisis especializado para factores dependientes con una escala ordinal. Para todas las variables con el número de grupos mayor que 2, se utilizó una variante multinomial. Introducido relativamente recientemente, el análisis ordinal tiene una serie de características. Toman en cuenta los detalles de la escala. Mientras tanto en los manuales metódicos, el ordinal regresión logística a menudo no considerado como un dispositivo separado. Esto se debe a lo siguiente: el análisis ordinal no tiene ninguna ventaja significativa sobre multinomial. El investigador puede usar el último si hay una variable dependiente tanto ordinal como nominal. Al mismo tiempo, los procesos de clasificación en sí mismos no difieren mucho entre sí. Esto significa que llevar a cabo un análisis ordinal no causará ninguna dificultad.
Opción de análisis
Considere un caso simple: regresión binaria. Supongamos que, en el proceso de investigación de mercado, se estima la relevancia de los graduados de una determinada universidad en la capital. En el cuestionario, a los encuestados se les hicieron preguntas, que incluyen:
- ¿Estás trabajando? (ql).
- Indique el año de graduación (q 21).
- ¿Cuál es el punto de graduación promedio (aver)?
- Sexo (q22).
Regresión logística evaluará el impacto de los factores independientesaver, q 21 y q 22 a la variable ql. En pocas palabras, el propósito del análisis será determinar el empleo probable de los graduados sobre la base de la información sobre el campo, el año de graduación y el puntaje promedio.

Regresión logística
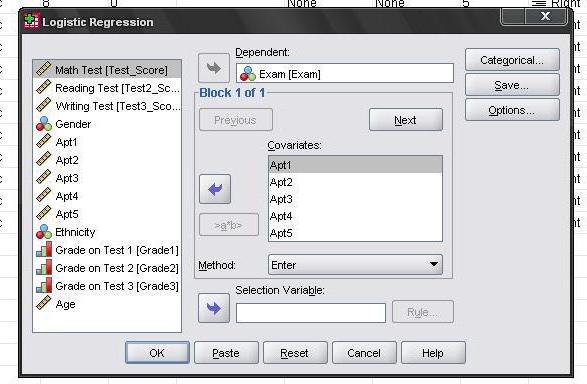
Para establecer los parámetros usando binarioregresión, debe usar el menú de análisis Analyse►Regression►Binary Logistic. En la ventana Regresión logística, debe seleccionar el factor dependiente en la lista izquierda de variables disponibles. Él es ql. Esta variable debe colocarse en el campo Dependiente. Después de eso, se deben introducir factores independientes en el sitio Covariables: q 21, q 22, aver. Luego debe elegir una forma de incluirlos en el análisis. Si la cantidad de factores independientes es mayor que 2, entonces no se utiliza el método de introducción simultánea de todas las variables, que se instala por defecto, sino que es un método paso a paso. La forma más popular se considera hacia atrás: LR. Con el botón Seleccionar, no puede incluir a todos los encuestados en el estudio, sino solo a una categoría objetivo específica.
Definir variables categóricas
El botón Categórico debe usarse encaso, cuando una de las variables independientes es nominal con el número de categorías mayores que 2. En esta situación, en la ventana Definir variables categóricas, este parámetro se coloca en la sección de Covariables categóricas. En este ejemplo, no hay tal variable. Después de eso, en la lista desplegable de Contraste, seleccione Desviación y presione el botón Cambiar. Como resultado, se formarán varias variables dependientes a partir de cada factor nominal. Su número corresponde a la cantidad de categorías de la condición original.
Guardar nuevas variables
Usando el botón Guardar en el cuadro de diálogo principalla investigación crea nuevos parámetros. Contendrán indicadores calculados en el proceso de regresión. En particular, puede crear variables que definan:
- Pertenecer a una categoría específica de clasificación (membresía de grupo).
- La probabilidad de asignar un encuestado a cada grupo de estudio (Probabilidades).
Al usar el botón Opciones, el investigador norecibe cualquier oportunidad significativa. En consecuencia, puede ser ignorado. Después de hacer clic en el botón "Aceptar", los resultados del análisis se mostrarán en la ventana principal.
Control de calidad de adecuación y regresión logística
Considere la tabla Omnibus Tests of ModelCoeficientes Muestra los resultados del análisis de la calidad de aproximación del modelo. En relación con el hecho de que se especificó una versión paso a paso, es necesario observar los resultados de la última etapa (Paso 2). Se considerará un resultado positivo que resulte en un aumento en el indicador de Chi-cuadrado cuando pase a la siguiente etapa con un alto grado de significación (Sig. <0.05). La calidad del modelo se evalúa en la línea Modelo. Si se obtiene un valor negativo, pero no se considera significativo en la gran importancia general del modelo, este último se puede considerar prácticamente útil.
Tablas
El Resumen del modelo brinda la oportunidad de evaluar el indicadorde la varianza agregada que describe el modelo construido (el indicador cuadrado R). Se recomienda usar el valor de Nagelker. Un indicador positivo es el parámetro Nagelkerke R Square, si está por encima de 0,50. Después de eso, se evalúan los resultados de la clasificación, en la que los índices reales de pertenencia a una u otra de las categorías estudiadas se comparan con los pronosticados sobre la base del modelo de regresión. Para hacer esto, usa la Tabla de clasificación. También permite sacar conclusiones sobre la corrección de la diferenciación para cada grupo bajo consideración.

La primera tabla, en la que hay importantesfiguras del investigador, - Información de adaptación del modelo. Un alto nivel de significación estadística indicará la alta calidad y la idoneidad de utilizar el modelo para resolver problemas prácticos. Otra tabla importante es Pseudo R-Square. Nos permite estimar la proporción de la varianza total en el factor dependiente, que está determinada por las variables independientes elegidas para el análisis. De acuerdo con la tabla Pruebas de razón de verosimilitud, puede sacar conclusiones sobre la significación estadística de esta última. En las Estimaciones de parámetros, se reflejan los coeficientes no estandarizados. Se usan en la construcción de la ecuación. Además, para cada combinación de variables, se ha determinado la significación estadística de su efecto sobre el factor dependiente. Mientras tanto, en la investigación de mercado, a menudo existe la necesidad de diferenciar por categoría de encuestados, no individualmente, sino como parte del grupo objetivo. Para hacer esto, use la tabla Observedand Predicted Frequencies.
Aplicación práctica
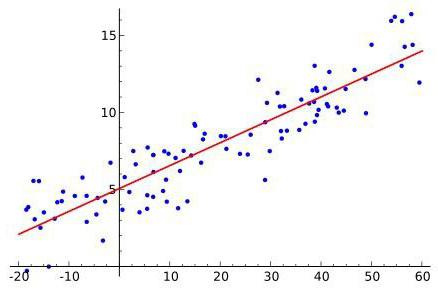
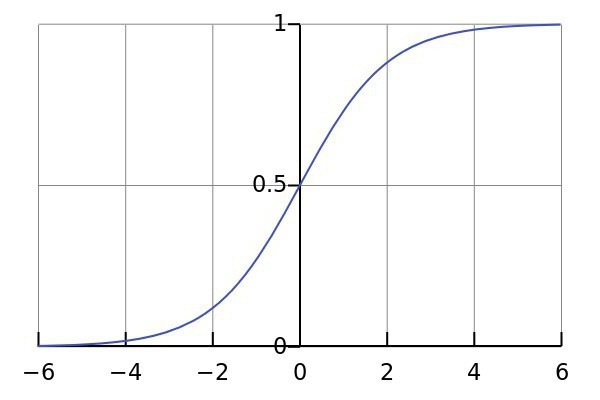
El método de análisis considerado es ampliamente utilizadoen el trabajo de los comerciantes. En 1991, se desarrolló un indicador de regresión sigmoidea logística. Es una herramienta fácil de usar y efectiva con la que puede predecir los precios probables antes de que "se sobrecalienten". El indicador se representa en el gráfico en forma de un canal formado por dos líneas que corren en paralelo. Están igualmente espaciados de la tendencia. El ancho del corredor dependerá únicamente del cronograma. El indicador se usa cuando se trabaja con casi todos los activos, desde pares de divisas hasta metales preciosos.
En la práctica, se han desarrollado dos estrategias claveaplicación de la herramienta: en el desglose y en un giro. En este último caso, el comerciante se guiará por la dinámica del cambio de precio dentro del canal. A medida que el costo se acerca a la línea de soporte o resistencia, la apuesta se realiza sobre la probabilidad de que el movimiento comience en la dirección opuesta. Si el precio se acerca mucho al límite superior, entonces el activo puede ser eliminado. Si está en el límite inferior, entonces vale la pena pensar en la adquisición. La estrategia de desglose implica el uso de pedidos. Se establecen fuera de los límites de una distancia relativamente pequeña. Teniendo en cuenta que el precio en varios casos los viola por un corto tiempo, debe ser reasegurado e instalar stop-loss. Al mismo tiempo, por supuesto, independientemente de la estrategia elegida, el operador debe ser lo más cool y fresco posible para percibir y evaluar la situación que ha surgido en el mercado.
Conclusión
Por lo tanto, la aplicación de la regresión logísticale permite clasificar rápida y simplemente a los encuestados en categorías de acuerdo con los parámetros especificados. En el análisis, puede usar cualquier método en particular. En particular, la regresión multinomial es versátil. Sin embargo, los expertos recomiendan el uso de todos los métodos anteriores en el complejo. Esto se debe al hecho de que en este caso la calidad del modelo será mucho mayor. Esto, a su vez, ampliará el alcance de su aplicación.




